Amazon Web Services has the ability to serve objects contained within an S3 bucket as a static website1. Upload some files to a bucket via their web-based console or via their API (as implemented in boto), flip a switch that indicates the bucket in question is to be used for this purpose:
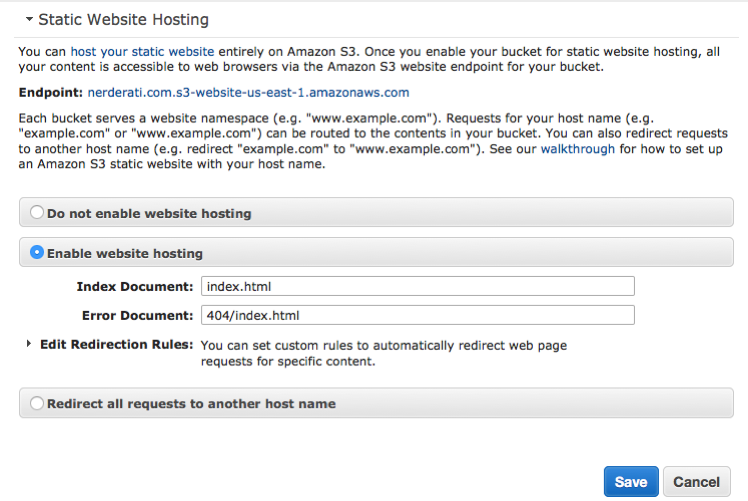
Next, ensure that you have the right set of arcane security policy directives, and then you can navigate to something like the-greatest-bucket.s3-website-us-east-1.amazonaws.com to see the fruits of your labour.
Add in the S3 SLA of 99.999999999% for object durability and 99.99% for general availability, the pricing model which makes it feasible to host a highly trafficked website for pennies per month2, and you have a very attractive option for anyone that doesn't require server-side processing for dynamic content3.
The Problem with Global Namespaces Is That They're Global
If you want to have https://nerderati.com backed by content in S3, you need to have a bucket named nerderati.com in your AWS account. This is because S3 uses the HTTP 1.1 Host: header to determine the bucket name, and is unaware of any CNAME/A records that may exist in DNS, and any such introspection would be one hell of a leaky abstraction, regardless.
S3 and Route53 are separate AWS products, and you are not required to use one service to be able to use the other: S3 does not care about which DNS provider you have chosen to use, and rightfully so.
But Why Is Uniqueness A Requirement?
To use an already overused journalistic cliché, global namespaces are typically considered harmful. They are, however, sometimes a necessary evil.
One of AWS S3's defining characteristics is that the top-level namespace is shared, across all users and regions, such that any bucket under any account must have a globally unique name.
There are several reasons for this, but one of them relates directly to what we're talking about: S3 was initially designed so that bucket contents could be accessed over HTTP, and this is still the primary use-case for most people today.
Since buckets can be accessed globally via a virtual-host style domain:
https://nerderati.s3.amazonaws.com
or a path-style domain:
http://s3.amazonaws.com/nerderati/index.html
it requires that bucket names be unique in the same way that canonical domain names and URLs must be unique.
The static website hosting capabilities of S3 relies on this property to perform the mapping between the resource requested over HTTP, and the location of said resource in the system. When using a path-based URL, the mapping is relatively simple. A request for http://s3.amazonaws.com/nerderati.com/index.html in your browser is translated into an HTTP 1.1 request:
GET /nerderati.com/index.html HTTP/1.1
Host: s3.amazonaws.com
Similarly, the virtual-host based URL of https://nerderati.com.s3.amazonaws.com/index.html becomes:
GET /index.html HTTP/1.1
Host: nerderati.com.s3.amazonaws.com
And if you wish to have your content available at a more user-friendly URL like https://nerderati.com, a simple A record in DNS allows for the same mechanism but with an additional DNS lookup in between to determine the mapping between nerderati.com and the associated virtual-host based bucket location:
GET /index.html HTTP/1.1
Host: nerderati.com
In all of these examples, S3 is able to decipher an exact, unambiguous name for the bucket in question without requiring any special headers or flags that a visitor to your site may not have configured.
Uniqueness and User-Specified Content
A problem quickly arises when you combine the following requirements:
- Allow users to select the name of a bucket
- Require that this name be globally unique
- Use the 1-to-1 mapping between
Host:header and bucket name for static website hosting
Namely, it becomes quite trivial for a malicious user to prevent another from using S3 to host their static site. If Alice wishes to prevent Bob from using the service to host his bobbytime.com site, all she needs to do is create a bobbytime.com bucket in her own account before Bob is able to. Once that occurs, there's nothing that Bob can do, short of pleading with AWS support staff, to create a bucket with the correct name.
CloudFront to the Rescue
The knee-jerk reaction to discovering the problem is to cry foul, and demand that AWS implement some sort of safeguard or secondary mapping option in the bucket (which would bring another set of problems to the table). The solution, however, is to use Amazon's content distribution network, CloudFront.
CloudFront allows you to configure a distribution, which is a logical set of objects that you wish to make available at the various data centres around the world:
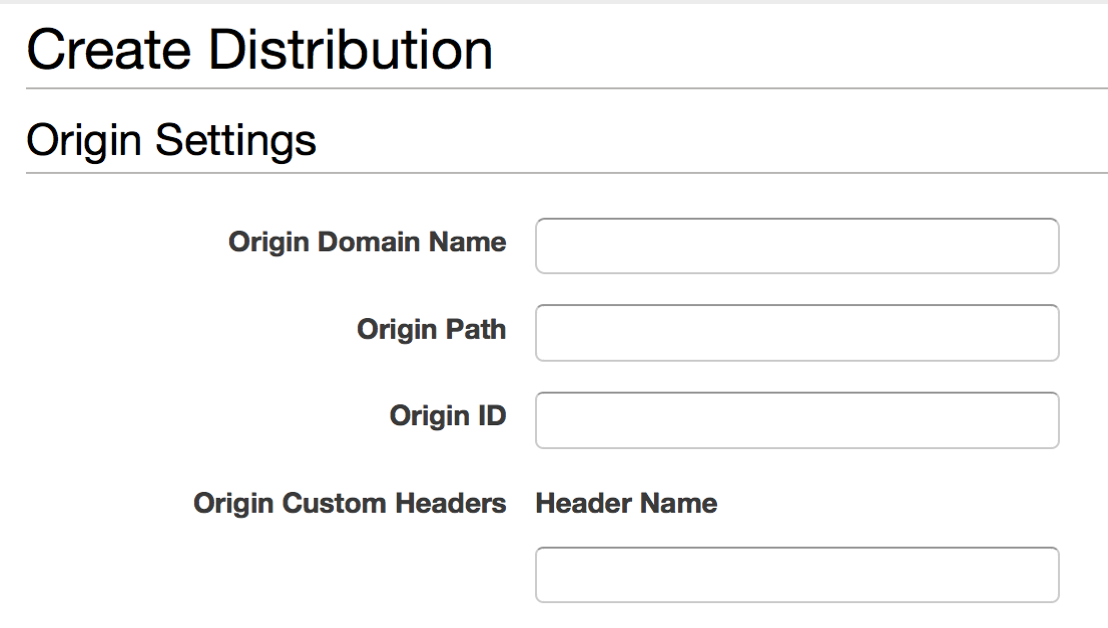
In configuring this distribution, you explicitly set the origin to an AWS S3 bucket (in our case, anyways – other origin endpoint types are possible). Couple that with a change in your DNS records to point your domain name to the CloudFront distribution endpoint, and you now have the ability to dissociate the S3 bucket name from the domain name that your content is served from: CloudFront, when fetching your S3 resources to prime the cache, will automatically rewrite the request Host: header to match the name of the S3 bucket origin, no matter what it's called.
This way, if someone has stolen your domain's bucket name, then you can bypass the problem entirely. It will, however, incur the additional costs that come with CloudFront, but you do get the benefits of a very powerful, well-supported CDN.
A static website is one that does not require server-side processing, and usually consists of HTML/CSS/Javascript, and images. As you may have already surmised, this blog is an example of a static site.
Hosting a website that receives ~300,000 object requests (each resource counts as a request, so a single HTML page with one external CSS file and one Javascript file would count as 3 requests) per month, with about 50GB of outbound bandwidth, would set you back about $4.50 USD.
With the introduction of AWS Lambda, the divide between so-called "static" websites and ones requiring dynamic content processing is slowly being eroded.